Guide complet du SHRINK dans SQL Server
Categories:
9 minutes à lire
Le SHRINK est une opération manuelle et ponctuelle, jamais automatisée ni planifiée.
Utilisez toujours DBCC SHRINKFILE sur un fichier précis, jamais DBCC SHRINKDATABASE.
Pour les gros fichiers, réduisez par petits incréments plutôt que d’un seul coup.
L’opération ne corrompt jamais la base : SQL Server est fiable.
Quand faut-il faire un SHRINK ?
Le shrink est déconseillé en règle générale. C’est une opération coûteuse qui fragmente fortement les index. Paul Randal, qui a développé la commande SHRINK dans SQL Server 2005, l’explique en détail : Why you should not shrink your data files.
Mais : si on vous demande de récupérer de l’espace disque, faites-le. C’est légitime. Le cas typique : une base qui a grandi suite à un import massif ou une opération ponctuelle, puis les données ont été purgées. Il reste un fichier de 200 Go dont seuls 20 Go sont utilisés. On vous demande de libérer l’espace : vous faites un shrink.
Vérifier l’espace utilisé
Avant de réduire quoi que ce soit, il faut savoir où en est l’utilisation de l’espace.
Rapport SSMS
Dans SQL Server Management Studio : clic droit sur la base de données > Rapports > Rapports standards > Utilisation du disque. Ce rapport affiche des camemberts qui montrent la répartition entre espace utilisé et espace libre dans les fichiers de données et de journal.
Requête sur les fichiers de données
La requête suivante interroge sys.database_files pour afficher la taille totale, l’espace utilisé et l’espace libre de chaque fichier de la base courante:
SELECT
name AS [nom_logique],
file_id,
CASE type_desc
WHEN 'ROWS' THEN 'DONNEES'
WHEN 'LOG' THEN 'JOURNAL'
ELSE type_desc
END AS [type],
size / 128 AS [taille_Mo],
FILEPROPERTY(name, 'SpaceUsed') / 128 AS [utilise_Mo],
(size - FILEPROPERTY(name, 'SpaceUsed')) / 128 AS [libre_Mo],
physical_name AS [chemin_physique]
FROM sys.database_files
ORDER BY type_desc, file_id;
Espace des journaux de transaction
Pour les fichiers de journal, utilisez DBCC SQLPERF :
DBCC SQLPERF(LOGSPACE);
Cette commande renvoie la taille du journal et le pourcentage utilisé pour chaque base de données de l’instance.
SHRINKFILE, pas SHRINKDATABASE
DBCC SHRINKDATABASE. Cette commande réduit tous les fichiers de la base sans distinction. Vous n’avez aucun contrôle sur le fichier ciblé ni sur la taille finale de chaque fichier. Utilisez toujours DBCC SHRINKFILE sur un fichier spécifique.Trouver le nom logique du fichier
DBCC SHRINKFILE attend le nom logique du fichier en premier paramètre. Pour le trouver (dans la base courante), utilisez cette requête :
SELECT
file_id,
CASE type_desc
WHEN 'ROWS' THEN 'DONNEES'
WHEN 'LOG' THEN 'JOURNAL'
ELSE type_desc
END AS [type],
name AS [nom_logique],
physical_name AS [nom_physique]
FROM sys.database_files;
Syntaxe DBCC SHRINKFILE
USE [MaBase];
GO
DBCC SHRINKFILE (N'nom_logique_du_fichier', 50000);
GO
Le premier paramètre est le nom logique du fichier. Le deuxième paramètre est la taille cible en Mo. Ici, 50000 Mo = environ 50 Go.
Utiliser SSMS pour générer le script
Vous pouvez aussi passer par l’interface graphique de SSMS pour générer la commande. C’est pratique pour les débutants :
Clic droit sur la base > Tâches > Réduire > Fichiers (Shrink > Files)
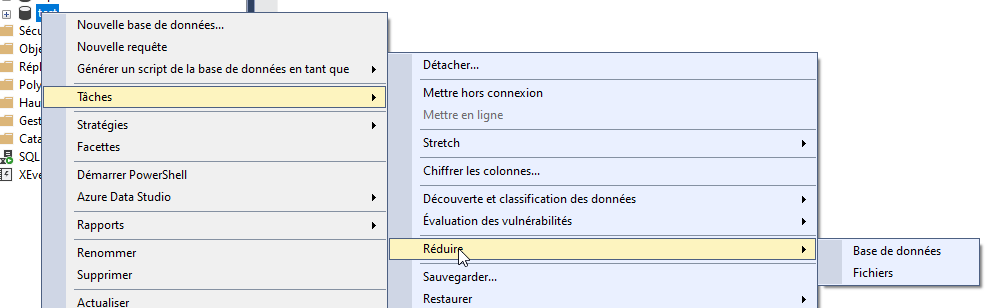
Sélectionnez le fichier et définissez la taille cible
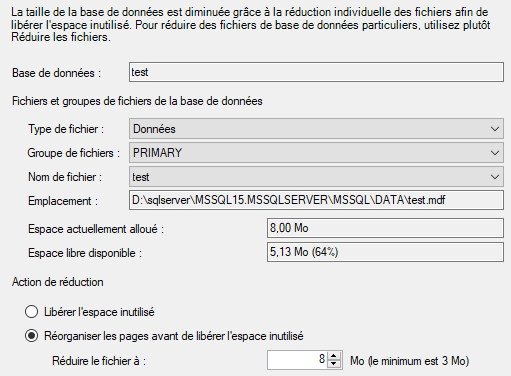
Cliquez sur Script pour générer la commande T-SQL dans une nouvelle fenêtre
L’avantage du script : vous voyez la commande, vous pouvez la modifier, surveiller l’exécution dans la fenêtre de résultats, et relancer facilement si besoin.
Comment le SHRINK fonctionne en interne
SQL Server prend les pages de données situées à la fin du fichier et les déplace vers le début, dans les espaces libres. C’est un mouvement physique de pages sur le disque. C’est pourquoi l’opération est lente et fragmente les index : les pages qui étaient contiguës et bien ordonnées se retrouvent dispersées.
L’opération est non bloquante : elle ne pose pas de verrous exclusifs de longue durée sur les tables. Les utilisateurs peuvent continuer à travailler pendant le shrink. Vous pouvez le lancer un week-end, mais si ça déborde sur les heures ouvrées, ce n’est pas dramatique.
Stratégie de réduction incrémentale
Réduire un fichier de données volumineux d’un seul coup peut prendre des heures, voire des jours. Plus le volume à déplacer est important, plus c’est long.
La solution : réduire par paliers. Au lieu de passer directement de 200 Go à 50 Go par exemple, descendez de 200 à 180, puis 160, puis 140, et ainsi de suite jusqu’à la taille cible. Selon les performances de votre disque et votre hardware, vous pouvez même agir par petits incréments, par exemple 25 Mo. Chaque étape termine plus rapidement, et vous avez un meilleur contrôle sur la progression.
Si vous perdez la connexion pendant un shrink, l’opération s’arrête proprement. La base n’est pas endommagée. Vous recommencez simplement depuis le dernier palier atteint. C’est un avantage supplémentaire de l’approche incrémentale : chaque palier atteint est définitif.
Script T-SQL incrémental
Le script suivant réduit un fichier par incréments de 10 Go :
USE [MaBase];
GO
DECLARE @nom_fichier sysname = N'MaBase'; -- nom logique du fichier
DECLARE @taille_cible_Mo int = 51200; -- 50 Go en Mo
DECLARE @increment_Mo int = 10240; -- 10 Go en Mo
DECLARE @taille_actuelle_Mo int;
DECLARE @nouvelle_taille_Mo int;
-- récupérer la taille actuelle
SELECT @taille_actuelle_Mo = size / 128
FROM sys.database_files
WHERE name = @nom_fichier;
PRINT 'Taille actuelle : ' + CAST(@taille_actuelle_Mo AS varchar(20)) + ' Mo';
PRINT 'Taille cible : ' + CAST(@taille_cible_Mo AS varchar(20)) + ' Mo';
SET @nouvelle_taille_Mo = @taille_actuelle_Mo - @increment_Mo;
WHILE @nouvelle_taille_Mo >= @taille_cible_Mo
BEGIN
PRINT '--- Réduction vers ' + CAST(@nouvelle_taille_Mo AS varchar(20)) + ' Mo ---';
DBCC SHRINKFILE (@nom_fichier, @nouvelle_taille_Mo);
SET @nouvelle_taille_Mo = @nouvelle_taille_Mo - @increment_Mo;
END
-- dernier palier exact vers la taille cible
IF @nouvelle_taille_Mo + @increment_Mo > @taille_cible_Mo
BEGIN
PRINT '--- Réduction finale vers ' + CAST(@taille_cible_Mo AS varchar(20)) + ' Mo ---';
DBCC SHRINKFILE (@nom_fichier, @taille_cible_Mo);
END
PRINT 'Terminé.';
GO
Adaptez les trois variables en haut du script : le nom logique du fichier, la taille cible et l’incrément.
Automatiser avec dbatools
Le module PowerShell dbatools fournit la commande Invoke-DbaDbShrink qui gère nativement la réduction incrémentale grâce au paramètre -StepSize.
# réduction incrémentale du fichier de données par paliers de 10 Go
Invoke-DbaDbShrink -SqlInstance "MonServeur" `
-Database "MaBase" `
-FileType Data `
-StepSize 10GB `
-ShrinkMethod Default `
-PercentFreeSpace 20
Paramètres utiles :
| Paramètre | Description |
|---|---|
-FileType | Data ou Log — type de fichier à réduire |
-StepSize | Taille de chaque incrément (ex : 10GB), vous pouvez utiliser la syntaxe MB, GB, TB supportée en PowerShell |
-ShrinkMethod | Default, TruncateOnly, NoTruncate |
-PercentFreeSpace | Pourcentage d’espace libre à conserver après le shrink |
Surveiller l’opération en cours
Le shrink peut durer longtemps. Pendant l’exécution, ouvrez une autre fenêtre SSMS et lancez cette requête :
SELECT
session_id,
start_time,
status,
DB_NAME(database_id) AS [db],
blocking_session_id,
wait_time,
wait_type,
wait_resource,
percent_complete,
total_elapsed_time
FROM sys.dm_exec_requests WITH (READUNCOMMITTED)
WHERE command IN (N'DbccFilesCompact', N'DbccSpaceReclaim')
OPTION (RECOMPILE, MAXDOP 1);
La colonne percent_complete vous donne une estimation de la progression.
percent_complete.Comprendre le statut
La commande peut être en RUNNING ou en SUSPENDED. Le plus souvent, elle sera en SUSPENDED : elle attend le système d’entrées/sorties pour continuer son travail.
La colonne wait_type indique la raison de l’attente. La colonne wait_time donne la durée de l’attente en cours (en millisecondes).
Les cas classiques :
PAGEIOLATCH_EX— Le SHRINK attend la lecture de pages de données sur le disque. Si le disque est lent ou saturé, vous verrez des attentes importantes de ce type.
Dimensionner la taille cible
Ne réduisez pas au maximum. Il faut laisser de la marge de croissance pour éviter des auto-growth fréquents.
Fichiers de données
La taille cible dépend de deux facteurs : la taille actuelle des données et le taux de croissance.
Exemple concret : votre base contient 20 Go de données. Si vous réduisez le fichier à 21 Go, il va falloir grandir à nouveau très vite. Visez plutôt 50 Go (x2,5 de marge). C’est une bonne moyenne pour la plupart des bases.
Pour estimer le taux de croissance, vous pouvez interroger l’historique des sauvegardes :
SELECT
database_name,
CAST(backup_start_date AS date) AS [date],
CAST(backup_size / 1024.0 / 1024.0 / 1024.0 AS decimal(10, 2)) AS [taille_Go]
FROM msdb.dbo.backupset
WHERE type = 'D'
AND database_name = 'MaBase'
ORDER BY backup_start_date DESC;
Cette requête montre l’évolution de la taille des sauvegardes complètes au fil du temps. Si la base passe de 18 Go à 20 Go en six mois, le taux de croissance est modéré et 50 Go de marge est confortable.
Fichier journal de transaction
La taille du journal dépend du mode de récupération et de la fréquence des sauvegardes de log.
- En mode SIMPLE : le journal se recycle automatiquement aux checkpoints. Il n’a pas besoin d’être très grand.
- En mode FULL (production) : le journal ne se recycle qu’après une sauvegarde de log. Sa taille dépend du volume de modifications entre deux sauvegardes.
Pour connaître la fréquence des sauvegardes de log, vérifiez dans les propriétés de la base (SSMS) la valeur Last Log Backup. Si le backup de log passe toutes les 15 minutes, le journal n’a pas besoin d’être énorme : en 15 minutes, il ne se produit généralement pas un volume considérable de modifications.
Pour aller plus loin sur les journaux de transaction, consultez l’article Journaux de transactions.
Après le SHRINK d’un fichier de données : reconstruire les index
Pour reconstruire tous les index d’une table :
ALTER INDEX ALL ON [schema].[table] REBUILD;
WITH (ONLINE = ON) en édition Enterprise.
Si vous avez des tables volumineuses, préférez un REORGANIZE qui est non bloquant, ou utilisez les scripts de maintenance d’Ola Hallengren pour faire du rebuild en ligne.Pour reconstruire tous les index de toutes les tables de la base, vous pouvez utiliser un curseur ou passer par dbatools ou utiliser les scripts de maintenance d’Ola Hallengren, qui sont la référence pour la maintenance des index en SQL Server.